Top 3 insights from using RPA+ML to automate invoice processing
Antti Rauhala
Co-founder
September 28, 2020 • 5 min read
This post appeared first on Towards Data Science in September 25th, 2020.
The RPA team of Posti, the Finnish logistics giant, started to use machine learning to boost their invoice automation. These are the key insights from that project. A good read for whoever is leading or contributing when taking existing automation and making it intelligent using machine learning.
You can read more about the project here. In short, the problem was that Posti receives ten thousand purchase invoices a month. For accounting, payment and taxation purposes, each invoice needs to be associated with 1) a reviewer 2) a budget/account 3) department and 4) value added tax code.
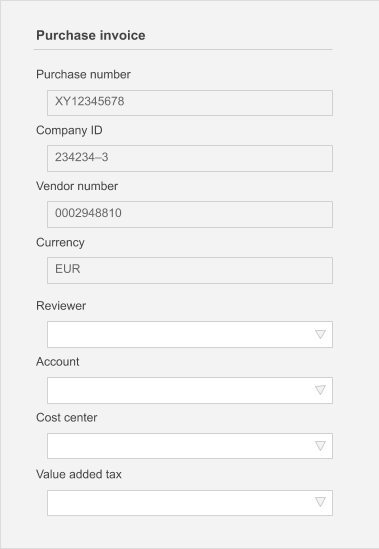
As a solution, UiPath was used to copy the historical invoices to the predictive database. Then the predictive database queries were used to predict the missing fields:
{
“from” : “purchase_invoices”,
“where”: {
“purchase_number “: “XY12345678”,
“company_id”: “234234–3”,
“vendor_number”: “0002948810”,
“currency” : “EUR"
},
“predict”: “reviewer”
}The predictions with high confidence/probability estimates were then used to fill the missing fields in the invoices by the RPA machinery and automate different phases of the process.
This is what we learned.
Insight 1: RPA+ML can be very rewarding
Process automation is a very rewarding field for machine learning application, because:
- Companies tend to have high quality and complete records of their core business processes, because the business cannot operate without those records (e.g. orders or invoices) and in the worst case there may be juridical implications (as with invoices), if the business records are not well maintained.
- Most processes have extremely strong patterns. For example, the invoices coming from ‘the Parking company’ tend to always go to the ‘parking budget’. Such patterns are very easy to harvest from data and utilize in process automation allowing for example 20%-99% automation rates in exchange for 1%-5% errors in the statistical process.
- Large companies can have a very high volumes in their core processes. For example: Posti processes about ten thousand invoices a month.
As consequence of good data, high automation rates and high volumes, the existing process data is often easy to untap and reuse in intelligent automation for a significant business gain.

Also based on the discussions with the Posti project team:
- RPA+ML projects are not that expensive compared to the traditional ML projects if done with a predictive database. Posti RPA team estimated that the median RPA project may take e.g. 3 months on average (there is typically a lot of analysis, communication and organizing overhead involved), while an RPA+ML project might take 4 months (extra month for the ML part, the extra data integrations, extra communication and the extra steps to handle possible errors). Still, it’s good to reserve significantly more time to the first RPA+ML project done by your organization.
- There are lot of use cases. It was estimated that 10%-20% of the Posti RPA use cases could benefit from the similar kind of machine learning.
- The business benefits of RPA+ML applications can be high: possibly hundreds of thousands of euros, because of high automation rates in moderately complex high volume processes
As a result of these discussions: the team did identify many rewarding business cases and opportunities and decided to expand the deployment of ML with the same setup of tools.
Insight 2: RPA+ML requires a business impact mindset
While in the traditional rule-based RPA you may have strong guarantees that the process is errorless, with the intelligent automation it’s difficult to create an entirely error-free solution. This applies because the machine learning component operates in a statistical fashion.

But while you cannot have a perfectly error-free system, what you can have is:
A controlled error rate. In the Posti case, the ML component was able to fill the missing tax code field in 99% of cases with less than 1% error and 63% of the cost center cases with less than 5% error rate. In the invoice automation case, the content is double-checked in accounting, so a small error rate is typically not an issue.
Radically higher automation rates for extremely complex systems. In the Posti case, you could see thousands or even tens of thousands of separate purchase invoice types & special cases. Developing and maintaining thousands of different rules to implement a rule-based RPA with high coverage is simply not feasible in such a case. While complex rule-based automation may manage to handle e.g. 10% of the invoices, I have seen 80% or 90% automation rates with ML based solutions.
In essence with RPA+ML: you accept a controlled error rate in exchange for a radically higher automation rate, lower maintenance cost and an ability to solve otherwise unsolvable problems.
In practice, this requires a change in the mindset and a straightforward discussion with the business owners about the statistical errors and the optimal error rate/automation rate trade-off. It may also require an additional step in the process to review and correct the statistical decisions with an error rate above 1%.

You can find more information about the topic in an TDS article about ML return on investment
Insight 3: With the right tools intelligent automation is not hard
In the implemented invoice automation, the basic interaction was simplistic:
- First, the RPA robot scrapes the processed invoice forms from the accounting system into the predictive database.
- Second, the robot reads the incoming invoices, makes 4 simple predictive queries to predict the missing fields
- Third, the robot uses predictions to write the missing fields into the accounting system and changes the invoice process state.
There are numerous RPA+ML problems that can be solved in a similar simple manner. In essence, whenever you see a process with a form it can likely be automated in the same way.
Still, while the RPA part can be relatively straightforward, the ML part can be the exact opposite. In a typical scenario, you’ll ask for the data science team time for fitting, deploying and integrating the 4 ML models, that do the predictions for the 4 different fields. The data science project can take a while, it can be expensive and in essence: the data science team will schedule the time according to their wider priorities and often RPA is not at the top of their list.
On the other hand, if you use a predictive database to query the unknown fields, the experience is similar to using an SQL database to query the known fields. This SQL-like experience is easy enough for most RPA developers and the related effort and the time investments fit better the tight RPA budgets and schedules. The inherent easiness of the approach was reflected by the Posti RPA developer comment: ‘What I most like in Aito is that it’s easy to use’. It was also observed that the database integrations were a rather small part of the project and that the approach allowed the RPA team to do RPA+ML autonomously.
So the right tools can make RPA+ML easy and let the RPA teams progress on their intelligent automation roadmap autonomously. Of the alternative ML tools available: the used predictive database seems especially promising, because the fundamental easiness of doing machine learning with predictive queries.
Conclusion and recommendation
RPA+ML creates immediate business impact, it doesn't require a data scientist and it doesn't need to be hard.
Yet, we have found that most companies have difficulties in recognizing RPA+ML use cases. This is quite understandable, because RPA teams often lack machine learning experience and expertise in the level most of the solutions in the market require.

As a consequence: while a company can have an abundance of good use cases, these can go largely unrecognized. Now to solve the issues regarding use cases:
- A simple thought exercise can help here. Like mentioned before: any business process that can be thought of as a form is a potential RPA+ML automation target.
- There are a lot of use case descriptions available online.
- Also you can always consult intelligent automation experts or vendors like us for advice.
If you have questions or comments about the topic, we are happy to help at https://aito.ai/contact-us/ or you can contact our RPA consultant friends at Sisua Digital. Sisua has a strong expertise in ML-supported RPA automation and they held an advisory role in the Posti invoice automation project.
Back to blog listAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429