Introducing concept learning to free you from feature engineering
Antti Rauhala
Co-founder
March 23, 2020 • 4 min read
We exist to help developers build predictive functionality extremely easily and fast. In order to fulfill this promise, Aito manages a machine learning pipeline inside the predictive database.
The pipeline does operations like statistical relation discovery, feature selection and Bayesian inference, while simultaneously drawing data and statistics from the deeply integrated database.
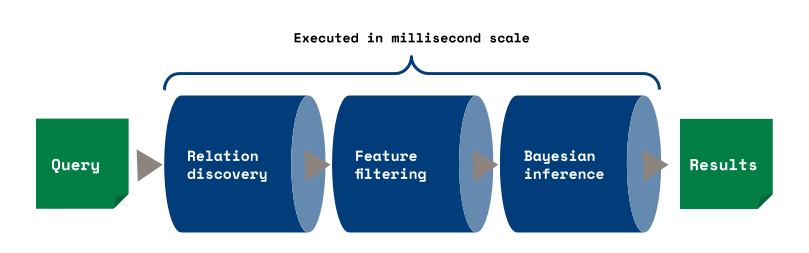
This pipeline is run in the millisecond scale and it is done fully automatically on the background so that you don't need to care about the mathematical details. This let's you predict e.g. a product category of an invoice with a simple predictive query like this:
{
"from": "invoices",
"where" : {
"Item_Description" : "machine learning"
},
"predict" : "Product_Category"
}Setting the ambition level
Yet, our ambition is to make Aito's use even easier and faster and there are things left that can be further automated and improved.
As an example, consider the following query with the $atomic keyword:
{
"from": "invoices",
"where" : {
"Item_Description" : { "$atomic" : "machine learning" }
},
"predict" : "Product_Category"
}The $atomic keyword is something we sometimes advise our customers to use to improve results.
Now, you might ask: "what is this $atomic thing?"
One answer is that $atomic is a utility for combining properties into a single bigger property. Such coupling of properties is sometimes done as a part of feature engineering.
There is also another more correct answer, which is simply that that you - as Aito's user - shouldn't need to care about the feature engineering. Heck, you shouldn't even need to know what feature engineering is.
Aito should take care of the feature engineering so that you don't need to.
Meet concept learning
We are introducing (end of March 2020) an MDL based feature learning method in Aito called concept learning. Concept learning is essentially a method for automatically creating higher order properties (called features in machine learning) from lower level ones. Concept learning recognizes patterns in data, and expresses these patterns as separate high level features. Often such features have 1-to-1 mapping to the concepts familiar to the people, thus the name.
Lets use animal data as an example. Concept learning may recognize a pattern of animals within the data walking like a duck, swimming like a duck and quacking like a duck. The component can then capture this pattern into the following Aito proposition:
{
"$and": [
{
"walking-like-a-duck": true
},
{
"swimming-like-a-duck": true
},
{
"quacking-like-a-duck": true
}
]
}If there are suprisingly many things walking like a duck, swimming like a duck and quackling like a duck, the above proposition will be formed to represent this pattern. In this case, the concept learning mechanism has correctly discovered the concept of the duck and Aito can then use the concept to make further predictions. For example: Aito could then reason that some specific duck may also fly like a duck.

In Aito's machine learning pipeline, concept learning essentially replaces Aito's feature filtering component:
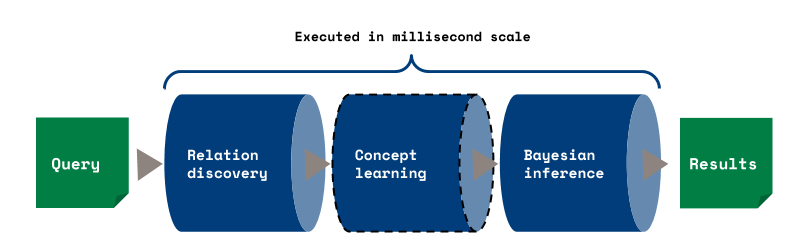
Previously Aito's feature filtering component would simply discard redundant features. Now Aito instead combines redundant features to form higher level features to be used in the Baysian inference. Like before, the concept learning is done in millisecond or 10 millisecond scale to provide instant responses to predictive queries.
Automatic feature engineering with invoices
The impact is most visible in the prediction explanations and in the probability estimates. To see how concept learning works: let's consider the invoice product categorization dataset from Kaggle covered in this blog post and the following query:
{
"from" : "invoices",
"where" : {
"Item_Description" : "Base Rent Store Management Fmc Corp Aug2017 Lease/Rent Real Estate"
},
"predict" : "Product_Category",
"select" : ["$p", "feature", "$why"]
}The query describes an invoice with a free text field about store management lease. Sending the request to Aito provides the product category CLASS-1274 as the top prediction with the probability of 98% and a detailed $why explanations for the results.
{
"offset": 0,
"total": 36,
"hits": [
{
"$p": 0.9839916759614079,
"feature": "CLASS-1274",
"$why": {
"type": "product",
"factors": [
{
"type": "baseP",
"value": 0.1761870760442699,
"proposition": {
"Product_Category": {
"$has": "CLASS-1274"
}
}
},
{
"type": "normalizer",
"name": "exclusiveness",
"value": 0.9844858670131971
},
{
"type": "relatedPropositionLift",
"proposition": {
"$and": [
{
"Item_Description": {
"$has": "manag"
}
},
{
"Item_Description": {
"$has": "store"
}
},
{
"Item_Description": {
"$has": "real"
}
},
{
"Item_Description": {
"$has": "rent"
}
},
{
"Item_Description": {
"$has": "leas"
}
},
{
"Item_Description": {
"$has": "estat"
}
},
{
"Item_Description": {
"$has": "base"
}
}
]
},
"value": 5.6353753851278805
},
{
"type": "relatedPropositionLift",
"proposition": {
"Item_Description": {
"$has": "fmc"
}
},
"value": 2.384000332140071
},
...cut for brewity...
]
}
},
...cut for brewity...
]
]The "$why" explanation contains the new part we are interested here. This one:
{
"type" : "relatedPropositionLift",
"proposition" : {
"$and" : [ {
"Item_Description" : {
"$has" : "manag"
}
}, {
"Item_Description" : {
"$has" : "store"
}
}, {
"Item_Description" : {
"$has" : "real"
}
}, {
"Item_Description" : {
"$has" : "rent"
}
}, {
"Item_Description" : {
"$has" : "leas"
}
}, {
"Item_Description" : {
"$has" : "estat"
}
}, {
"Item_Description" : {
"$has" : "base"
}
} ]
},
"value" : 5.6353753851278805
}The component describes that CLASS-1274 probability is elevated by a factor of 5.64, because the invoice contains the combination of terms: 'manag', 'store', 'real', 'rent', 'leas', 'estat' and 'base'. This combination of features has been formed by concept learning to represent a pattern that the concept learner has found to be common.
We can dig deeper into this concept by using it to query rows matching its condition.
{
"from" : "invoices",
"where" : {
"$and" : [ {
"Item_Description" : {
"$has" : "manag"
}
}, {
"Item_Description" : {
"$has" : "store"
}
}, {
"Item_Description" : {
"$has" : "real"
}
}, {
"Item_Description" : {
"$has" : "rent"
}
}, {
"Item_Description" : {
"$has" : "leas"
}
}, {
"Item_Description" : {
"$has" : "estat"
}
}, {
"Item_Description" : {
"$has" : "base"
}
} ]
}
},
"orderBy" : "$similarity",
"select" : ["$highlight"]
}
It occurs, that the pattern is extremely common. In fact, there are 945 such rows of which the first 8 ones look the following (formatted for readability):
- 2008-Nov First Real Estate Investment Trust Of New Jersey Base Rent Lease/Rent Store Management Real Estate
- Store Management Base Rent Real Estate Lease/Rent Dec-2004 First Real Estate Investment Trust Of New Jersey
- First Real Estate Investment Trust Of New Jersey 2005Sep Store Management Real Estate Lease/Rent Base Rent
- Apr2005 California Real Estate Investment Trust Base Rent Lease/Rent Store Management Real Estate
- Base Rent Jul2009 Store Management California Real Estate Investment Trust Real Estate Lease/Rent
- Real Estate Lease/Rent Base Rent Bradley Real Estate Inc Jun2000 Store Management
- Store Management Base Rent Real Estate Lease/Rent Jul2006 Continental Real Estate Partners Ltd
- Real Estate Store Management Lease/Rent Base Rent Oct-2004 Derand Real Estate Investment Trust
We can see that the concept's invoices concern store rents and leases. All of the concept's invoices belong to the product category CLASS-1274. In fact almost all of CLASS-1274's 981 invoices also belong to the discovered concept and there is almost 1-to-1 mapping between the automatically discovered concept and the CLASS-1274 product category.
The main benefit of the concept learning mechanism is that it helps to eliminate the need for manual feature engineering. Also with the concept learning: Aito no longer confuses concepts like 'machine learning' with likes of 'machine maintenance' or 'corporate learning'. This makes things easier for you as an Aito user and it provides more precise and robust results.
Try it yourself!
If you want to test the concept learning in practice, please go to https://aito.ai/request-trial/ and ask for a free sandbox instance. This RPA blog post provides rather clean instructions for getting some sample data, and putting it in. Then try the queries shown in this post.
Back to blog listAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429