15min solution to missing data problem in RPA
Tommi Holmgren
Chief Product Officer
February 14, 2020 • 5 min read
99.8% accuracy to predict a product category from invoice data. Done in 15 minutes. See how, and try yourself!
Missing data is everywhere
Recent months have brought several interesting customer cases to us at Aito, and we are looking forward to telling you more about them soon! Meanwhile, I wanted to explore a common use case using a public dataset that allows you to experience Aito's superpowers firsthand.
Robotic Process Automation (RPA) users very commonly encounter problems with missing data points in the inputs of their automations. When data is partially unavailable, it makes the automation as useful as a broken bridge, and automation remains low, as human still needs to provide inputs. We were recently helping a customer predict several datapoints in purchase invoice processing: VAT category, factual checker, PO number, debet class and so on.
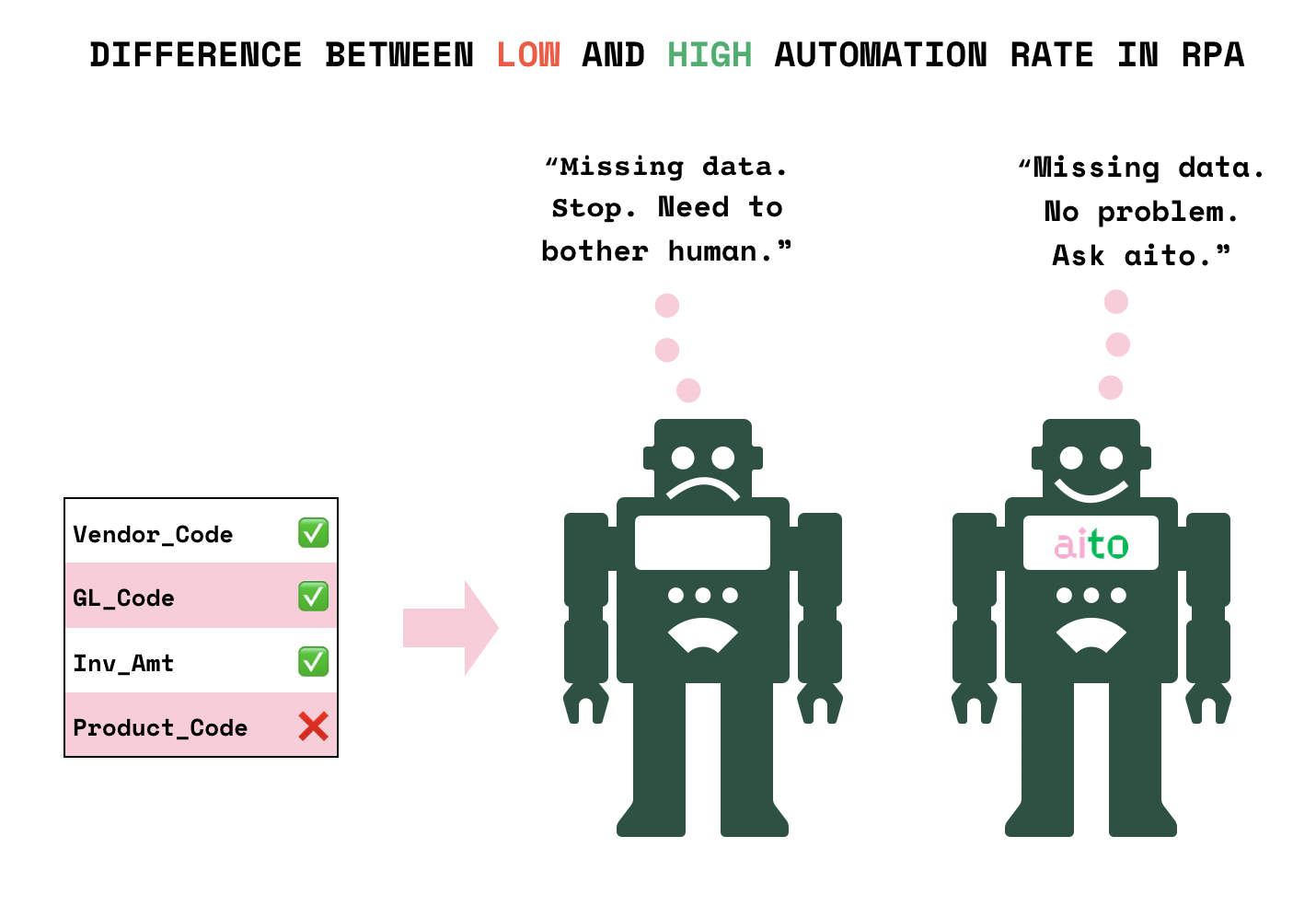
Now, building a missing value prediction machine with modern ML tools and libraries is not a huge feat for a data science professional. Yet, we see typically RPA teams lacking access to those resources. Second, there is the sheer speed of implementation. It took me less than 15 minutes to have a live prediction API endpoint (not including writing this blog), and I am certainly not an experienced developer - it's way over 10 years since my active developer times!
Dataset
I found a simple dataset in Kaggle with a target to predict a product category from available details. This has been used as a hiring challenge for data scientists in India.
We have a training set (Train.csv) of 5566 rows of comma-separated values including the target variable Product_Category, it looks like this. For improved readability, the description field is concatenated in the table.
| Inv_Id | Vendor_Code | GL_Code | Inv_Amt | Item_Description | Product_Category | ||
|---|---|---|---|---|---|---|---|
| 15001 | VENDOR-1676 | GL-6100410 | 83.24 | Artworking/Typesetting ... | CLASS-1963 | ||
| 15002 | VENDOR-1883 | GL-2182000 | 51.18 | Auto Leasing Corporate ... | CLASS-1250 | ||
| 15004 | VENDOR-1999 | 6050100 | 79.02 | Store Management Lease/Rent ... | CLASS-1274 | ||
| ... | ... | ... | ... | ... | ... |
Each row represents invoice data, with vendor code Vendor_Code, general ledger code GL_Code, invoice amount Inv_Amt and a textual description of what was invoiced Item_Description. You will see later, but I chose not to use the running number Inv_id in the predictions, as it would not add value.
Kaggle dataset comes with a test set (Test.csv), which does not contain ground truth. That's why we, later on, evaluate Aito's performance by setting aside part of the training set for test purposes.
How to implement missing value predictor with Aito
Aito is a predictive database, which runs machine learning inference directly within the database, based on queries resembling SQL. Aito is well suited for classification tasks with dynamically changing prediction target (new Product_Category values are automatically incorporated to predictions).
Prerequisites
First, you will need an Aito instance to replicate the steps below yourself. That is the hardest part, as we still have a waitlist for new accounts. You can get your spot in the queue here, and after contact me in our public Slack workspace to get your quicker. But do not tell ANYONE. ;) Once you get access, you'll create an instance and have its name and API keys at hand.
Second, I'm assuming you have installed Aito CLI tools and set up necessary environment variables.
Upload the dataset with CLI
I'm using Aito CLI tools for an amazingly quick data upload. Having a simple CSV file like ours, quick-add-table does exactly what is needed. It infers the Aito schema from the dataset, creates a table with the schema and uploads the dataset. All in one command.
I am changing the filename to something more intuitive like InvoiceData.csv, as it's used to name the table.
mv Train.csv InvoiceData.csv
aito database quick-add-table InvoiceData.csvReview schema
Next, I am checking that the schema Aito inferred looks sensible. (Sidenote: I'm doing all the Aito queries from command line so that they are quick to copy to your own terminal. You can accomplish the same results by sending requests with a REST client like Insomnia.)
curl -X GET \
https://$AITO_INSTANCE_URL/api/v1/schema/InvoiceData \
-H "x-api-key: $AITO_API_KEY" \
-H "content-type: application/json"The output is the schema (below), and by the looks of it all is correct. Aito has decided that the Item_Description field should be analyzed in English. Aito supports other analysers, but let's not get sidetracked.
{
"columns": {
"GL_Code": {
"nullable": false,
"type": "String"
},
"Inv_Amt": {
"nullable": false,
"type": "Decimal"
},
"Inv_Id": {
"nullable": false,
"type": "Int"
},
"Item_Description": {
"analyzer": "english",
"nullable": false,
"type": "Text"
},
"Product_Category": {
"nullable": false,
"type": "String"
},
"Vendor_Code": {
"nullable": false,
"type": "String"
}
},
"type": "table"
}Run a prediction
Because I'm impatient, I just want to run a prediction right away. I chose a random row from the Test.csv and use that to predict Product_Category that is missing. I'll do that with Aito's _predict API endpoint.
Let's look at the query that goes into my request body. I'm defining the "knowns" in a where-clause, meaning the values I get from my chosen test data row. Then I set the prediction target to be Product_Category, limiting to top the three predictions only.
curl -X POST \
https://$AITO_INSTANCE_URL/api/v1/_predict \
-H "x-api-key: $AITO_API_KEY" \
-H "content-type: application/json" \
-d '
{
"from": "InvoiceData",
"where": {
"GL_Code": "GL-6101400",
"Inv_Amt": 55.93,
"Item_Description": "Arabian American Development Co Final Site Clean Up 2008-Oct General Requirements General Contractor Store Construction",
"Vendor_Code": "VENDOR-1254"
},
"predict": "Product_Category",
"limit": 3
}'The response body is what we are looking for. It looks very promising! Pay attention to the first element. $p is showing that Aito is very sure (99.9%) that Product_Category is CLASS-1522, and nothing else. Following two predictions are extremely unlikely, having $p value close to zero.
{
"offset": 0,
"total": 36,
"hits": [
{
"$p": 0.9998137062471193,
"field": "Product_Category",
"feature": "CLASS-1522"
},
{
"$p": 7.345473788575557E-5,
"field": "Product_Category",
"feature": "CLASS-1828"
},
{
"$p": 3.118734024876525E-5,
"field": "Product_Category",
"feature": "CLASS-1983"
}
]
}But wait! What if the $pis not that high? Most of our customers choose a threshold (like 90% or higher) and use the prediction result in automation if probability exceeds the threshold. Anything lower, the case is returned for human processing with suggestions.
Evaluating accuracy
Aito has inbuilt functionality to evaluate the accuracy of the models. We discussed that in the earlier post so follow the link for more info.
With the query below Aito splits the data into two parts: test set (every third entry) and training set (the rest) and then automatically runs test queries and returns results. If you want to try this yourself, you'll need to familiarise yourself with Aito's Jobs, all explained in the same article as above.
{
"test": {
"$index": { "$mod": [3, 0] }
},
"evaluate": {
"from": "InvoiceData",
"where": {
"GL_Code": {"$get": "GL_Code"},
"Inv_Amt": {"$get": "Inv_Amt"},
"Item_Description": {"$get": "Item_Description"},
"Vendor_Code": {"$get": "Vendor_Code"}
},
"predict": "Product_Category"
},
"select": ["trainSamples", "testSamples", "accuracy", "error"]
}Once the above query is posted as a job, and Aito finishes running it, you are able to fetch the result, which looks like this:
{
"trainSamples": 3711.0,
"testSamples": 1856,
"accuracy": 0.9983836206896551,
"error": 0.001616379310344862
}With 1856 test samples, Aito's accuracy was 99.8%. Pretty awesome for 15 minutes effort.
Operationalise
At this point, you actually have a fully functional prediction service (requests we were sending to _predict earlier) running in the cloud, and you could just start shooting in more queries just like the one above. Magic, right!
In a real-life scenario, you might have an initial training dataset as a starting point. Afterwards, new data points are added to Aito from automation script. Aito will use all the new data without the need for a separate process to re-train and deploy models, learning as you go.
Here is how to add new data points one by one using Aito's database API.
curl -X POST \
https://$AITO_INSTANCE_URL/api/v1/data/InvoiceData \
-H "content-type: application/json" \
-H "x-api-key: $AITO_API_KEY" \
-d '
{
"GL_Code": "GL-9900990",
"Inv_Amt": 39.00,
"Inv_Id": 34001,
"Item_Description": "Predictive database monthly subscription, developer tier",
"Product_Category": "CLASS-9999",
"Vendor_Code": "VENDOR-9999"
}'Comparison
I'm not going to scientifically benchmark accuracies here, as I am pretty sure almost every ML lib and tool can get good results with this simple dataset. I am just offering my subjective view as a non data scientist (and barely a developer) for a couple of alternatives below. My focus was on what it takes to get this done - with my skills.
First, there is a kernel that implements the same thing with XGBoost, yet I bet whoever made it has spent quite a bit more time than I did and he was a data scientist. Accuracy was the same.
I also wanted to see if a fully UI driven AutoML tool could do this for me. I tried MyDataModels. Generating the model took about 12h and after that predictions returned an error. They claim to be a Small Data Prediction Company, but for me it remains a mystery how small the data needs to be.
Next up, I checked Uber's Ludwig, that is promised to be a toolbox allowing training and testing deep learning models without the need to write code. I got started fairly ok, and got Ludwig to train the network for me. It seemed really complex to comprehend. The only reason I understood a little bit of what was happening is because I've been working through the popular Stanford Machine Learning course lately. Without that, I would have been completely clueless. So Ludwig is absolutely not democratising anything. After an impatient but manageable wait, I had a model. With 94.8% accuracy. Not horrible, but my motivation to think how to use this in production stopped here. Maybe Ludwig is meant for something else?
Summary
I was able to create a production-grade version of a missing data prediction service in about 15 minutes with Aito. That alone is quite amazing considering my data science skills are very limited, and as a developer I'm outdated. Groundbreaking for RPA teams with engineers but possibly getting no TLC from data scientists.
Aito can be used to predict any of the missing fields in the dataset with the same simplicity. I did not touch this in the prediction part, but you can essentially just change the knowns and predict another variable. There is no static trained model that restricts the predictions. By having data uploaded in Aito you have already done the majority of the work.
Check out our other use cases or join our Slack community to give me feedback, and talk with the team!
Back to blog listAddress
Episto Oy
Putouskuja 6 a 2
01600 Vantaa
Finland
VAT ID FI34337429